The meta-analysis can be done using following models.
1. Fixed effect model
2. Random effects model
Selection of appropriate model depends upon the heterogeneity amongst the included studies. (see below for details)
Fixed effect meta-analysis: Steps
1. Calculating / extracting effect size:
(There is remarkable inconsistency in formula used for effect sizes in available literature. Users are advised to look at the
following formulae used by this software to calculate effect sizes and their confidence intervals)
A. Cohen's d (Hedges' g or Standardized Mean Difference : SMD)
Cohen's d = (M1 - M2) / SDPooled
Where,
M1 and M2 are means of outcome variable in treated and control group, respectively.
N1 and N2 are sample sizes in treated and control group, respectively.
SDPooled = sqrt[(N1-1) * SD1 + (N2-1) * SD2] / (N1+N2 - 2))
SD1 and SD2 are standard deviations of outcome variable in treated and control group, respectively.
B. Hedges' g* (Bias corrected)
Hedges' g* = Hedges' g x (Correction factor)
Where,
Correction factor = Exp[lgamma(df/2) - log (sqrt(df/2)) - lgamma((df-1)/2)]
Exp= exponent
lgamma = log gamma function
df= N1 + N2 - 2
This is extremely difficult to calculate. (This software uses above exact method to calculate Hedges g*)
However, following approximate method can also be used to calculate Hedges g*.
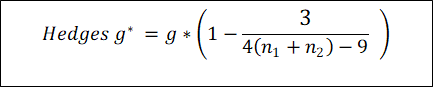
g = uncorrected Hedges g
C. Glass's Delta (Glass's Δ)
Glass's Delta = (M1 - M2) / SDControl
2. Calculating Variance (V) for selected effect size
Variance (V) for Cohen's d = 1/N1 + 1/N2 + d2 / (2* N1 + 2 * N2)
Variance (V) for Hedges' g* = 1/N1 + 1/N2 + g*^2 / (2 * N1 + 2 * N2)
Variance (V) for Glass's Delta (Δ) = 1/N1 + 1/N2 + Δ2 / (2 * N2)
SE = sqrt(V)
3. Weights (W) of each included studies under fixed effect model (inverse variance method)
Wi = 1/Vi
4. Summary effect size (MAES) under fixed effect model is calculated as follows
MES = Σ Wi * Y i / Σ Wi
Wi= Weight for ith included study
Yi= Effect Size for ith included study
5. Standard Error of MAES = 1/ ΣWi
Once summary ES and its standard error is calculated, it is fairly easy to calculate confidence intervals
of Summary ES.
6. Z value and p value.
Once summary ES and its standard error is calculated, it is fairly easy to calculate Z value and p value using normal distribution.
Z = MAES / SE
If available data is Effect Size (Cohen's d, Hedges' g, Glass's Delta or Hedges g*) and its confidence interval, then SE of the ES is calculated from UB and LB of confidence intervals, as follows.
SE = (UB - ES) / Z1−α/2
It can be also calculated as follows
SE = (ES - LB) / Z1−α/2
Variance (V) = SE2
Measures of heterogeneity
Not all included studies are homogeneous with respect to characteristics of participants such as age, gender, geo-environmental factors, other socio-demographic factors,
selection criteria for cases etc. When these differences are present, variability in the study results is not just random, and the
studies are considered as heterogeneous. This heterogeneity is quantified by following measures of heterogeneity.
1. Cochran's Q statistics
Q = Σ Wi * (Yi - M)2
Yi = effect size for ith study
M = Summary ES (MAES)
Q statistics follows chi-square distribution with k - 1 degrees of freedom (k= number of included studies)
So,
p value for Cochran's Q statistics can easily be calculated using chi square distribution.
Significant p value indicates that significant heterogeneity is present, and we should consider other methods of
meta-analysis like random effects model or sub-group analysis or meta-regression.
2. Tau squared (τ2) statistics
τ2= (Q - (k -1)) / C
where,
C = Σ Wi - Σ Wi 2 / Σ Wi
Σ Wi = Sum total of weights of all included studies
Σ Wi2 = Sum total of squared weights of all included studies
3. I2 statistics
I2= 100 * (Q - (k -1)) / Q
I2 statistics is measured in percentage. I2 value of < 25% is considered as low heterogeneity,
between 25 and 50 it is moderate and above 50% it is significant heterogeneity.
All above measures of heterogeneity provides a quantified measure, but they can not identify the factors causing heterogeneity.
Random effects model
If fixed effect meta-analysis shows significant heterogeneity (by Cochran's Q or I2 as explained above), then random effects model is one way to deal
with heterogeneity.
In random effects model (DerSimonian‐Laird), weights of each study are revised as follows .
WRE = 1/ (V + τ2)
There are other methods used for random effects model such as maximum likelihood, restricted
maximum likelihood (REML), Paule‐Mandel, Knapp‐Hartung etc. However, DerSimonian‐Laird method is most widely used and robust.
Then, summary ES under random effects model is calculated as follows
MAES = Σ WRE.i * Y i / Σ WRE.i
MAES = Summary Effect Size
WRE.i= Revised weight for ith included study
Yi= Effect Size for ith included study
Standard Error of MAES = 1/Σ WRE.i
Once summary ES and its standard error is calculated, it is fairly easy to calculate confidence intervals
of ES.
Z value and p value.
Once summary ES and its standard error is calculated, it is fairly easy to calculate Z value and p value using normal distribution.
Z = MAES / SE
Prediction interval is calculated using following formula.
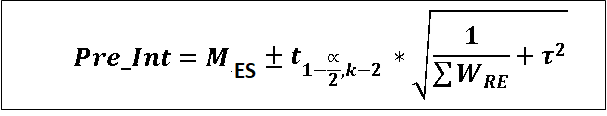
Where, t1-α/2, k-2 is (1−α/2)% percentile of t distribution with significance level α and k−2 degrees of freedom,
(k = number of studies included in the meta-analysis).
Interpretation: There is a 95% (or any other specified) probability that a newly conducted study will have effect size between this interval.
Galbraith Plot
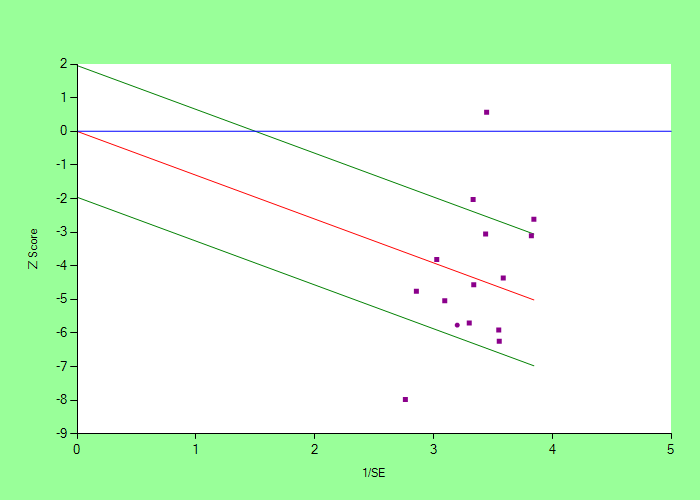
The Galbraith plot can also provide graphical representation to assess heterogeneity in the included studies.
It is a scatter plot of Z value against precision (1/SE) of each included studies. (Z value of each study = ES / SE).
The central horizontal blue line represents the line of null effect. Studies above this line has
positive effect size, indicating Group 1 mean is more than Group 2 mean. Studies below this line has negative effect size, indicating Group 1 mean is less than Group 2 mean.
Middle red line represents the MAES. (Its slope is equal to the MA ES). Studies above this line has more effect size than summary ES. Studies below this line has less effect size than summary ES.
Two green line (above and below middle red line), represents the confidence intervals of MAES.
In the absence of significant heterogeneity, we expect that about 95% (or other specified level) studies lie between the two green lines, and 5% (or other specified level) lie outside this. If more number of studies are
outside these lines, then it indicates significant heterogeneity.
In this Galbraith plot,
three studies are above the top green line and one study is below bottom green line. So a total of 4 studies, out of 15 included studies are not within the zone bounded by two green lines, suggesting heterogeneity.